
Database
PortADa Project Workflow (diagram already available on the website)
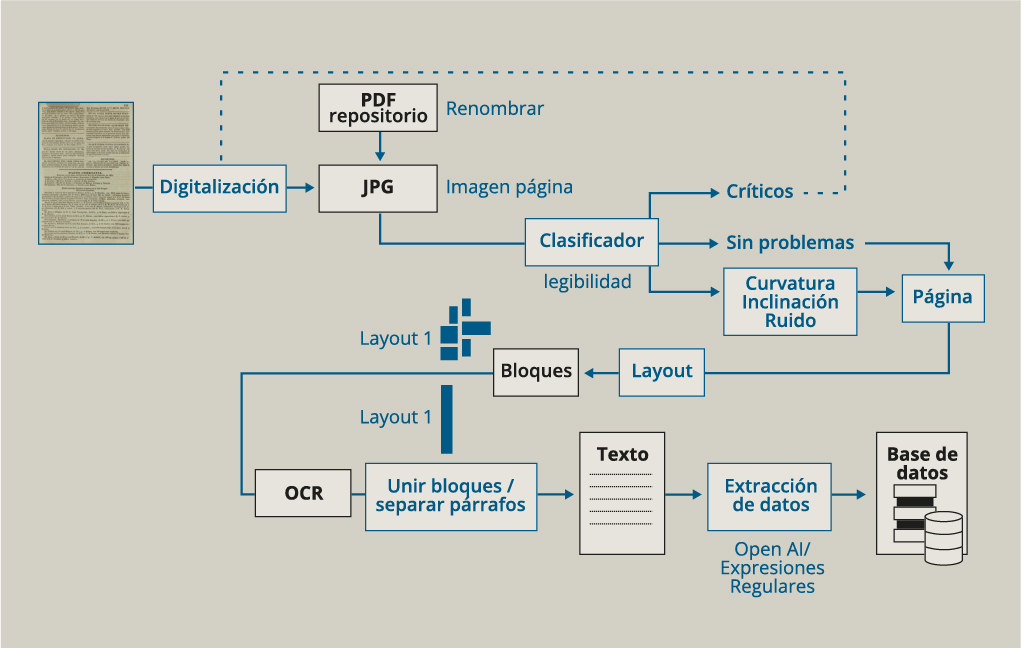
How the PortADa database is built
The project draws on information published in the local press of each port city regarding the arrival of ships from various origins. For Barcelona (Spain), Marseille (France), and Havana (Cuba), most sources were already digitised in historical digital newspaper repositories.
Images, sometimes available in PDF format, were converted toJPG. For Buenos Aires (Argentina), due to the lack of digitised material, relevant data for the project were captured through photography.
The image filenames were standardised using the following metadata: publication date, newspaper name, edition, issue number, position, page, and segment.
Once digitised, the workflow comprises four stages: correction, layout, optical character recognition (OCR), and data extraction.
To select the most appropriate methods for each stage, trial runs were carried out with different tools. All selected processes have been integrated into software called PAPICLI, allowing non-technical users to carry out each phase of the workflow autonomously.
The images we work with must be high-quality and sharp enough for letters and numbers to be clearly distinguishable. Using deep neural networks (ResNet model), an automatic classifier was developed to distinguish critical images —which require re-digitisation— from those suitable for processing.
A filtering software was applied to the useful images, separating them based on key OCR-related issues: curvature, noise, and tilt. This separation enables the application of targeted solutions for each image.
Although most digitised material appears as full pages, our interest lies in the port arrival notices, which occupy only part of those pages. Therefore, once the images are corrected, layout processing begins. This step involves segmenting the newspaper image into blocks (sections, columns, paragraphs). For this purpose, the YOLO (You Only Look Once) algorithm and Arcanum’s Newspaper Segmentation API were used alternately.
With the images segmented, we proceeded to the OCR phase, for which Google’s Document AI was employed. After character recognition, paragraphs were reassembled to reconstruct the daily port arrival news items for each newspaper. Each ship entry was then placed on a separate line.
These entries are used for data extraction to populate our database. We employed regular expressions and OpenAI tools to organise the extracted information according to predefined fields.
